3.1 Stochastic Properties of Random Matrix Factors
This is a consolidated post containing three former posts on stochastic factorization.
3.1.1 Stochastic Properties of Random Matrix Factors - 1
In this series of posts, we will be considering the stochastic properties of factors of random matrices. At first, we look at the simple case of Cholesky decomposition of Wishart matrices. More below.
Let be a matrix whose elements are random variables, each with a given distribution. Now assume that we factorize using one of the matrix factorization techniques such as QR, Eigenvalue, or Cholesky decomposition. The elements of the matrix factor are also random variables… but what are their distributions?
This is exactly what we hope to answer.
First and the obvious reason to find the distributions is to understand the characteristics of the matrix factor. For example, in a wireless communication MIMO channel, which is a zero-mean Gaussian random matrix, it helps us understand the stochastic properties of a ”partial” or ”inverse” channel.
The second reason is to speed up simulations. If we have a simulation that requires a random matrix factor which is computed numerically, the simulation may be sped up by generating the elements of the matrix factor directly with the given distributions.
Now we look at the stochastic properties of Cholesky decomposition of Wishart matrices.
Let be a complex-valued matrix whose elements are Gaussian random variables i.e. . Let . (Wishart matrix) is now a Hermitian symmetric complex-valued matrix.
It is well known that the Cholesky decomposition of is the upper triangular matrix from the QR decomposition of , i.e. where for a Unitary matrix and an upper triangular matrix with positive diagonal elements .
Therefore, the distribution of is straightforward from [6] and is given as follows:
where denotes Gaussian distribution and the Chi distribution with degrees of freedom.
Stochastic properties of the matrix factors may also be verified numerically. Let be a real-valued matrix with elements distributed according to standard Gaussian distribution, i.e. ’s are . given by:
Figure below illustrates the distributions of elements of computed numerically using MATLAB. Normalized numerical quantities obtained over 100000 trials are plotted in the blue bar graph and the theoretical expectation is plotted in red. Numerical results closely match the theoretical expectation.
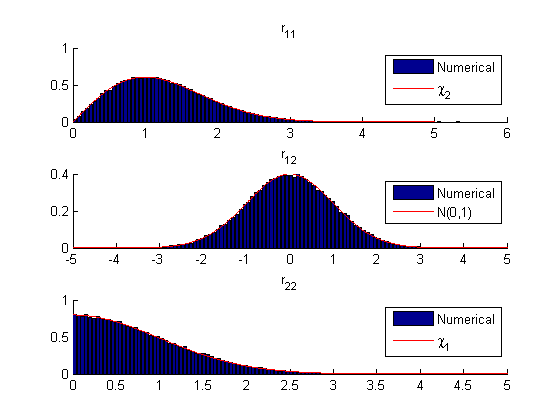
In the next blog posts on this topic, I hope to be able to provide more examples for stochastic properties of matrix factors especially the ones we come across in wireless communication.
Version History
-
1.
First published: 22nd Sep. 2015 on aravindhk-math.blogspot.com
-
2.
Modified: 17th Dec. 2023 – Style updates for LaTeX
3.1.2 Stochastic Properties of Random Matrix Factors - 2
In the second on the series of posts on stochastic properties of factors of random matrices, we look at a yet another simple case involving norm square of elements of QR decomposition of a scaled Rayleigh matrices. More below.
In applications such as Non-Orthogonal Multiple Access (NOMA), the so-called ”path loss” plays an important role whereby a channel matrix at a receiver is better modelled as a scaled Rayleigh matrix given by
where is the path-loss factor and the conventional Rayleigh matrix with real and imaginary parts of the elements each .
Let (by QR decomposition) where is a Unitary matrix, and is upper triangular. The distribution of the norm square of elements, , of is given by
where , , and denotes the Gamma distribution with probability density function
where is the complete Gamma function.
The stochastic properties of the diagonal elements of are interesting as they can be used to derive insights, amongst others, about mutual information of ”layers” (i.e. parallel streams of information, one per row) or the determinant of the covariance matrix of .
Figure below illustrates the distributions of elements of for computed numerically using MATLAB. Normalized numerical quantities obtained over 100000 trials are plotted in the blue bar graph and the theoretical expectation is plotted in red. Numerical results closely match the theoretical expectation.
![[Uncaptioned image]](figs/008_001_smf-2.png)
ARK
Version History
-
1.
First published: 25th Aug. 2017 on aravindhk-math.blogspot.com
-
2.
Modified: 17th Dec. 2023 – Style updates for LaTeX
3.1.3 Stochastic Properties of Random Matrix Factors - 3
In this third post continuing QR and related Cholesky matrix decomposition techniques, we look at the probability density function (PDF) of a diagonal element of the QR decomposition of a complex-valued random matrix with circular Gaussian i.i.d elements.
Let denote an matrix with circular Gaussian independent and identically distributed (i.i.d) elements with zero mean and variance two i.e. . Furthermore let denote the upper-triangular matrix obtained after QR decomposition () such that the diagonal elements of are non-negative. It is well-known that such a QR decomposition (QRP or QR with positive diagonal elements) of a matrix is unique. In case a QR decomposition algorithm results in negative diagonal elements, non-negativity may be arranged by multiplying those rows of and the corresponding columns of by -1.
It is well known that the diagonal elements of follow the distribution:
where denotes a Chi-distributed random variable with degrees of freedom.
From the above, it follows that the distribution of a diagonal element of the matrix may be given as the (equal) weighted sum of the pdfs of the diagonal elements as
where is the Gamma function.
The following graph shows the results of a MATLAB simulation for over 100000 iterations where the diagonal values of were collected. The blue graph shows the histogram of the diagonal values. The red graph shows the pdf as obtained using the equation above. We notice that the two correspond well.
![[Uncaptioned image]](figs/010_001_frx.png)
ARK
Version History
-
1.
First published: 29th Dec. 2017 on aravindhk-math.blogspot.com
-
2.
Modified: 17th Dec. 2023 – Style updates for LaTeX